
Internet penetration and increasing broadband speeds have collectively given rise to online businesses of all sizes, cutting across various businesses such as eCommerce, online media, jobs, travel, financial services, and so on. As CxOs and decision makers of these online businesses, you are constantly on your toes when it comes to IT security. You have no choice but to protect your Web property from cyber-attacks, and servers and databases from DDoS/XSS/SQL injection attacks. You have to take these security measures to ensure content delivery to your end users and businesses don’t get affected.
Despite ensuring all security measures, what if your content is always under the threat of being stolen? Always under the threat of someone extracting data from your website? The data that you spent days or months to create. The data that took a lot of intellectual capital to come up with. Online businesses can’t afford to remain complacent, nor in denial mode, that this is hard to happen with so much security practices in place. Web scraping happens!
Scrapers use bots (Web robot) that automatically execute scripts to perform the scraping operation. A scraper can set up virtual machines, activate proxies, and start sending malicious bots for a little under AUD 400.
The most common technologies used for scraping are cURL, Wget, HTTrack, Scrapy, Selenium, Node.js, PhantomJS. These are just a few and there are hundreds of Web scraping tools and services available to anyone who wants to illegally scrape data from your website.
But here, we'll take the example of Google spreadsheets, a tool commonly used by many for productive purposes, and give you an idea on how it can be used for scraping. Also, let’s look at some considerations while blocking such attempts and provide some recommendations.
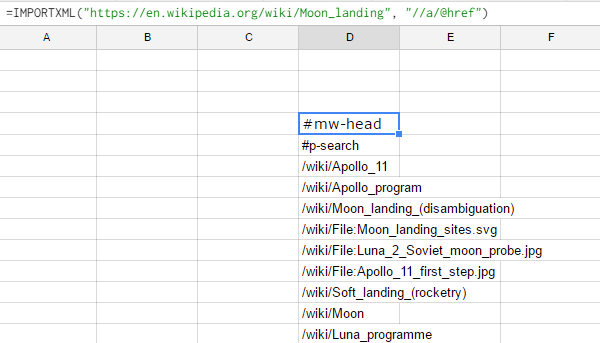
Google sheets is a popular tool among scrapers. Scrapers mostly use the IMPORTXML(
Step-1: Open Google Sheet
Step-2: In one cell, enter “=IMPORTXML("https://en.wikipedia.org/wiki/Moon_landing", "//a/@href")”
(or) you can enter your website link.
Step-3: You will observe that all the href references contained in the URL: https://en.wikipedia.org/wiki/Moon_landing , were extracted using the IMPORTXML command. The scraper can further execute scripts to extract other information from each of these links.
Sifting through server logs: Difficult to detect and take action
Data extraction requests made using these spreadsheets originate from Google's infrastructure: for example, those IP addresses making the requests through Google spreadsheet may be originating from google-proxy-xxx.xxx.xxx.xxx.google.com domain. Also, other important Google services like search bots (crawlers) also originate from Google's infrastructure.
Suppose you sift through your server logs, which by itself is a laborious process, and find the suspect IPs. You may be tempted to block these IPs on your firewall. However, you may inadvertently be blocking Google’s search engine crawler IPs, and this action will be disastrous to your SEO.
To make sure you don’t block genuine Google IP addresses, Google recommends using their reverse DNS verification to identify if an IP is from their infrastructure. So, if you suspect an IP, use the host command to determine whether the domain name is from google.com or googlebot.com.
Example from Google:
> host crawl-66-249-66-1.googlebot.com
crawl-66-249-66-1.googlebot.com has address 66.249.66.1
The problem here is, when someone executes data scraping through Google sheets, a reverse DNS operation might return a valid Google domain. In other words, the scraper will be able to extract data from your website using IMPORTXML command.
How do you deal with this?
Google sheets, used by many, was created for productive purposes. Unfortunately, scrapers are misusing the product to gain an unfair advantage over your website and business.
The example above is one of the simplest methods of Web scraping. There are other sophisticated methods that scrapers use, and the bots they create have evolved to mimic human behavior. Manually detecting and blocking these bots is tough, time-consuming, and in so many ways, unproductive.
Having said that, an automated bot prevention solution will be fully equipped to detect these type of scraping activities, based on bot signatures, behavior and patterns. Here are some tips and parameters to consider when choosing the bot detection software for your business:
1. Don’t block any of your genuine users - to ensure zero false positives
2. Scalable and geographically distributed solution - to cope up with increasing traffic, and cater to your businesses spread outside of your home base
3. Blanket solution, or want to implement bot protection only on certain sections of your website - to restrict bot detection on high impact pages
4. Equipped to take action against advanced bots - bots mimicking human behavior should be detected as well
I think asking this question “are you planning to safeguard your online business from bad bots?” may be irrelevant. The right question you must ask yourself is, “When?”.
Narendran Vaideeswaran, Director Product Marketing, ShieldSquare https://www.shieldsquare.com